How to Lose Money Online (Fast)
Two pictures, a lot of money, and some questions. Why I received a warning letter and you might receive one too.

One thing that always makes me nervous: a spike in visits on the legal notice page of this website. What are people looking for there? It can't be good!
In Germany, we have something that makes people like me nervous: cease-and-desist letters ("Abmahnungen"). A cease-and-desist letter is a "friendly" notice that something has gone wrong, but legal action or similar would be waived if a certain amount of money is paid and the issue is resolved.
I've already had the pleasure twice.
I always take care not to step on anyone's toes on my site. I avoid cookies wherever possible, no nasty pop-ups, and of course, I don't just use other people's images on my site, paying attention to copyright.
In the past, I've often told people that they can't just search for images on Google and use them on their websites. Naturally, I never do that either – except for…
Case 1: Twitter
My first cease-and-desist letter arrived after I deactivated my Twitter account and published my archive on this website. I went through the entire archive and replaced all media I had shared but not created myself with placeholders.
I thought I had been very thorough, reviewing my tweets several times, which was quite a substantial task after over 15 years on Twitter.
Nevertheless, I got a letter by a law firm on behalf of a major press agency. I had allegedly used one of their images without permission. Had I missed something?
The "convenient" thing about these cease-and-desist letters is that they include direct links to the pages and images referenced. In this case, it was a single tweet in the archive that contained a screenshot. Uh-oh… the screenshot showed a snippet of a news page: title, teaser, and the main image of a news story.
The main image in this screenshot was from the press agency. Damn!
I wasn't entirely sure (and still am not). I hadn't directly used the image; it was part of this screenshot. The screenshot was also old, having been posted on Twitter several years earlier. But frankly, I didn't feel like pursuing the matter further, so I paid, deleted the image, and shortly afterward, the entire archive because I found it too risky as a result.
Case 2: Open Graph
You probably know what an Open Graph image is, right?
A brief digression: when you share a link somewhere, e.g., on Mastodon, not only is the link displayed, but you also see a small preview consisting of a title, teaser, and often an image. These pieces of information are stored on the website as Open Graph data.
If you view the source code of this page, you will find such data here as well:
<meta property="og:title" content="Do not show stuff - Maurice Renck">
<meta property="og:description" content="You see me here, sitting at the keyboard with red and blue fingers. I just gave myself a good slap on the fingers.">
<meta property="og:image" content="https://maurice-renck.de/en/blog/2025/do-not-show-stuff/og-image">
<meta property="og:image:width" content="1600">
<meta property="og:image:height" content="900">
This data is hidden in the page header, not displayed, but is intended to be read and used by services like Mastodon:
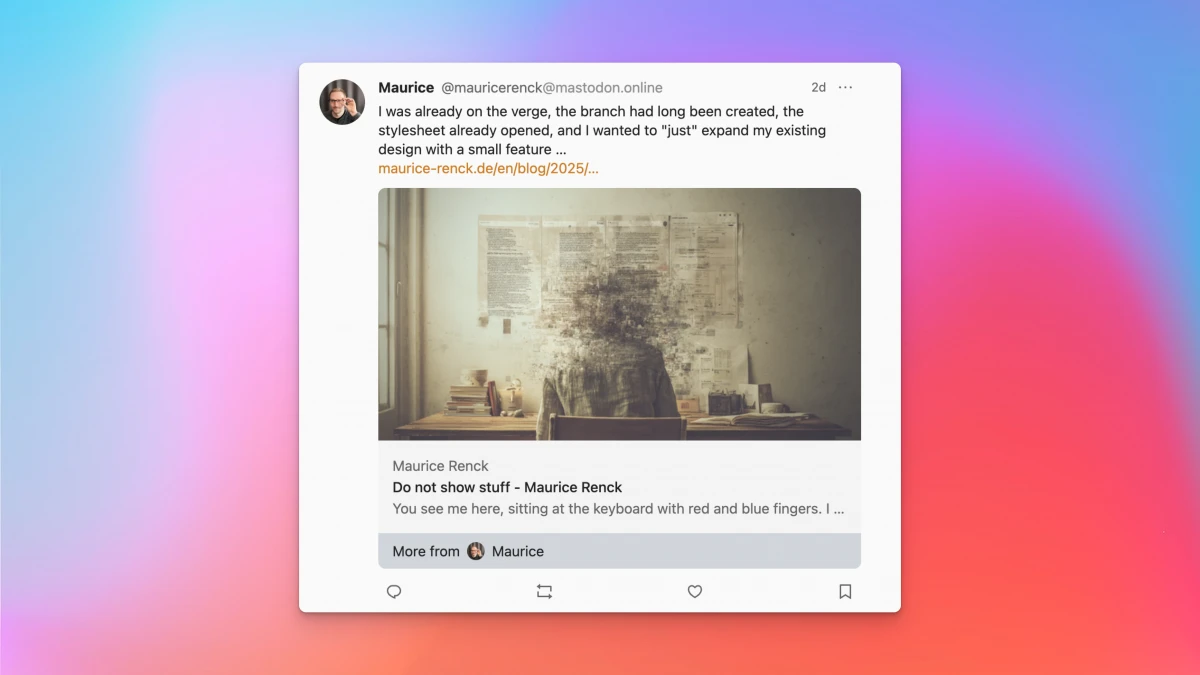
For me as a website operator, this is a good thing because a plain text link naturally attracts much less attention than such a nice preview. That's why many websites include this data. I even provide a plugin for Kirby that generates such an image.
So, when you share a link to a website on Mastodon, Facebook, LinkedIn, etc., it is very likely that these services will generate and display such a preview.
I also like link or bookmark cards. You might know them from Medium or Ghost, where they are quite popular. A link to my website then looks like this:
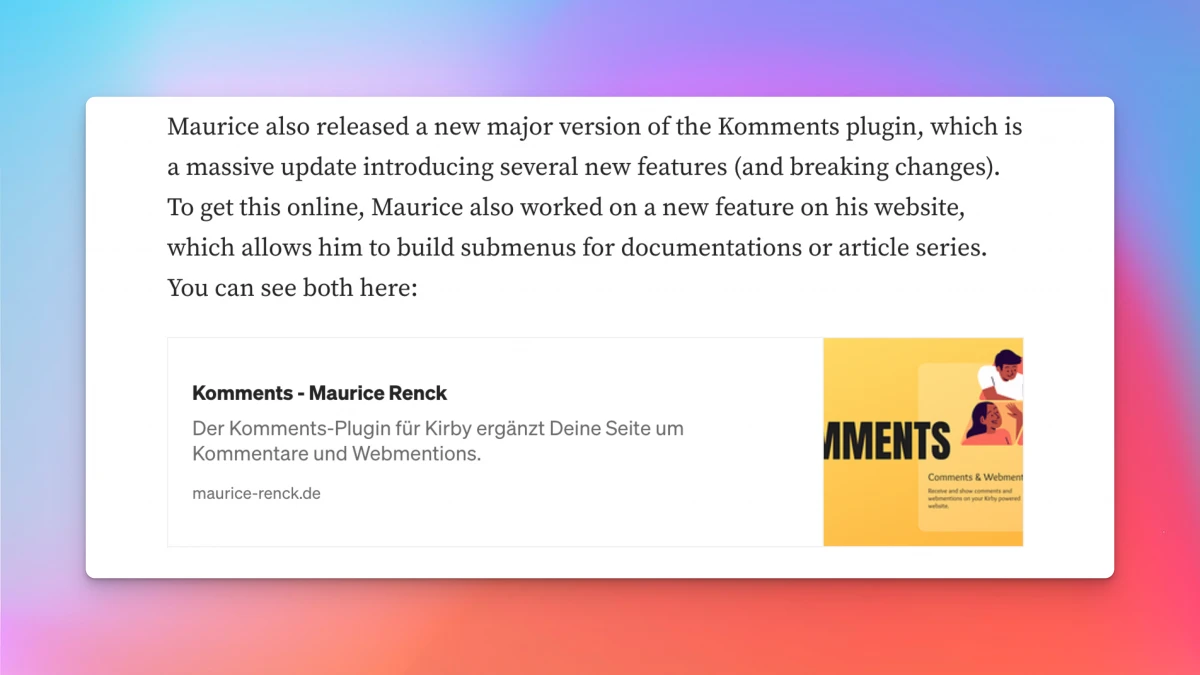
As you can see, a small box is displayed, and similar to Mastodon, the Open Graph data is read and displayed. The Open Graph image is also used for this.
I wanted to have that on my site too, so I wrote a plugin, years ago that calls all the links on a page and retrieves this Open Graph data. I just needed a way to display it.
To do this, I wrote a Kirbytag that takes a URL, queries the saved data, and then displays such a card.
This:
( embed: https://maurice-renck.de/de/kirby/ogimage )
becomes:
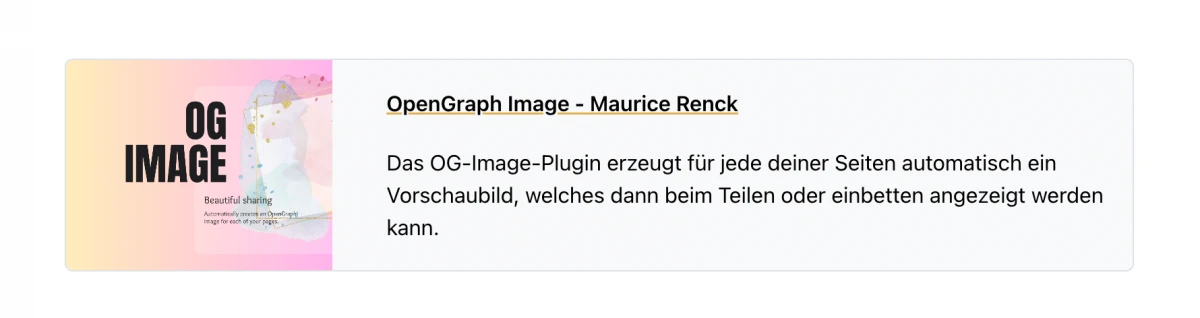
Nice, isn't it?
I constantly use these cards in my notes. I two types of notes: simple text notes and bookmarks. Bookmarks always have a link and a link card.
On the long note list, many links can appear, and to prevent the page from becoming unnecessarily slow, I resize and cache the image. An Open Graph image is about 1600×930 pixels, way too big for such a small preview.
The attentive reader may guess that the drama is slowly unfolding here.
On my link list, I had linked an article from the "taz", retrieved the Open Graph data, and displayed a card, including the linked image provided by the aforementioned press agency.
Finally, some mail in the mailbox!
The next cease-and-desist letter…
Again, well-documented as to which image in which post was the issue. So, I deleted the cache and rewrote the Kirbytag to initially display only the (fav)icon.
But…
I Have Questions
I understand that by caching the images (and thereby creating a copy), I probably at least entered a gray area, but I see that almost every service mentioned above does the same thing:
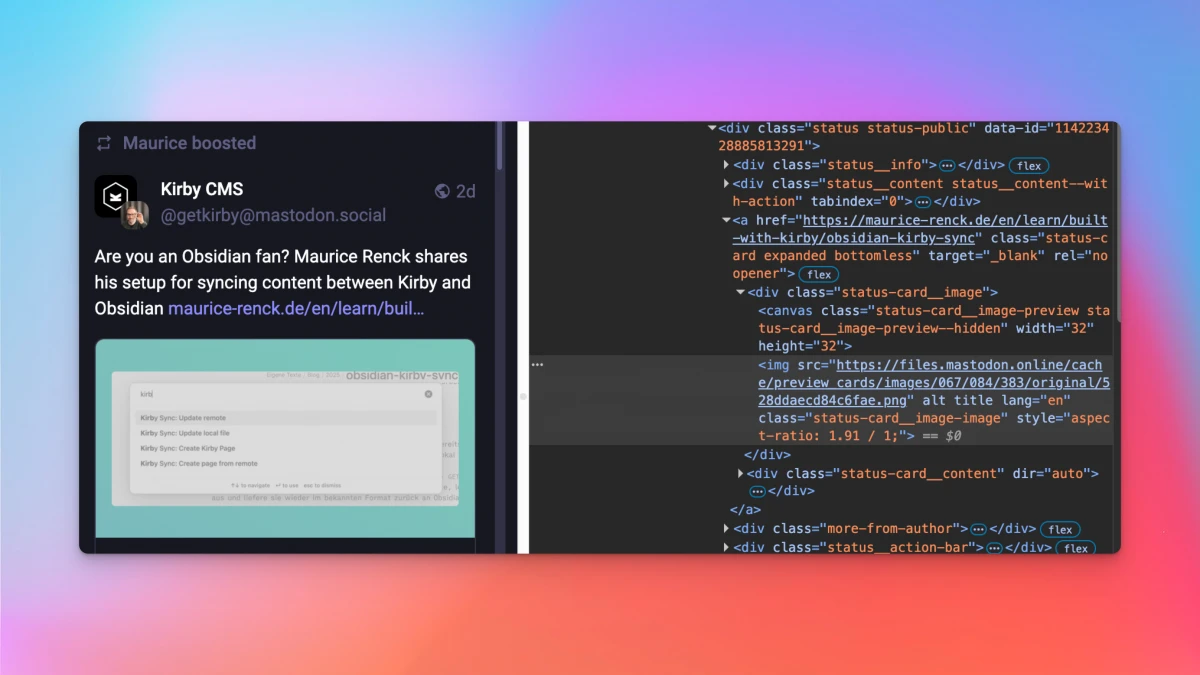
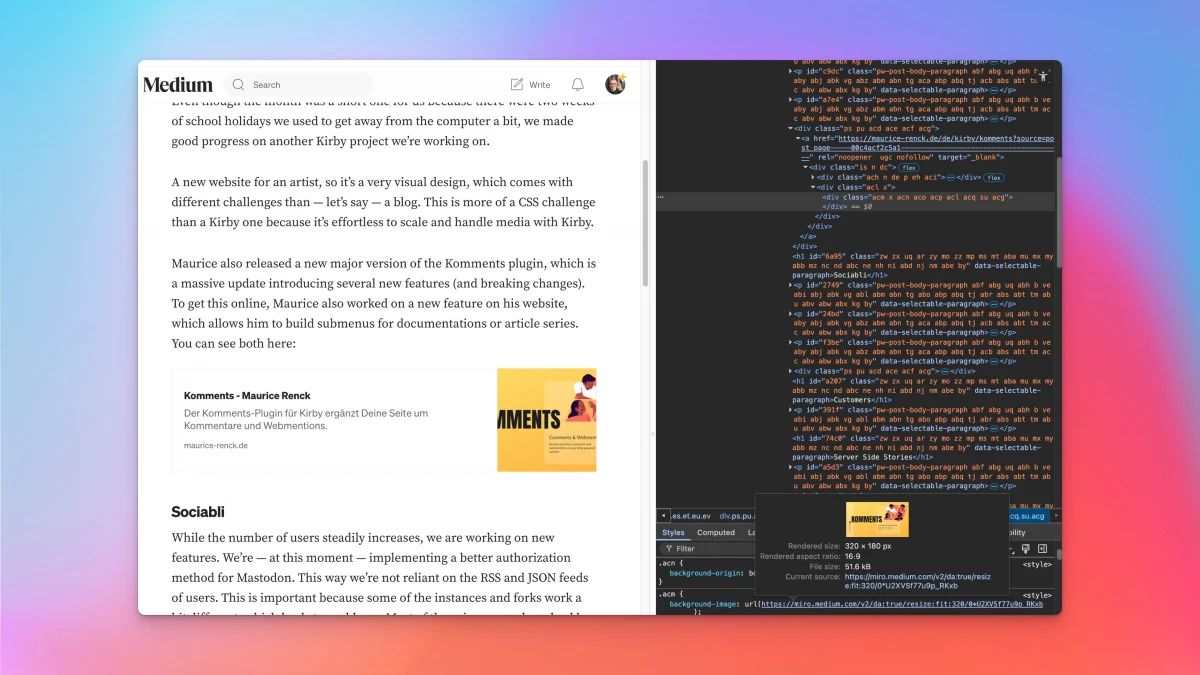
Here, too, images are resized and cached, as you can see when looking at the image URLs. Why aren't they drowning in cease-and-desist letters?
If a page defines an image as an Open Graph image and there is no licensing that permits embedding this image on other pages, why am I being punished for using it and not the site operator?
News sites often use images from such press agencies and also define them as Open Graph images. I can imagine how this works: someone sets a lead image in the CMS, and the system automatically sets it as the Open Graph image. The person responsible probably isn't even aware of this.
I would rather not assume malice here, but isn't this a massive trap for everyone who displays Open Graph data and can then be held liable?
Revenue Streams
Of course, no one should just use images (or other works) on their website without permission. Photographers should be fairly compensated for their work.
Anyone with a bit of technical knowledge can quickly figure out how it all came about.
In both cases, the service Pixray was used, as I could quickly determine from the log files. This service apparently searches the web for its clients' images, after which they can take action.
A brief look at the site made me decide to pay and not pursue the matter further, since it emphasizes that cease-and-desist letters are part of the business model. It says:
You should have a clear goal for how much revenue you want to make from copyright enforcement this year, next year and in the years that follow.
So, I didn't hold out much hope for a different resolution. Maybe I acted a bit hastily — who knows.
Conclusion
The technical conclusion is explained quickly: No more displaying Open Graph images. The embed Kirbytag was reworked so that it no longer displays these images unless I explicitly allow it via a parameter or the URL belongs to a list of sites where it’s okay.
Aside from the technical implementation, I still find all of this questionable and puzzling. It’s probably a gray area, and since my site has a readily accessible legal notice page, it’s easier to go after me than an anonymous Mastodon account.
However, I would argue that most website operators assume they are allowed to use an Open Graph image as such. This image is explicitly marked to be displayed when shared. And no one would use an almost 2000px wide image for a small preview—or at least, I hope not.
If I use this data, I would have to research every link from now on to see whether the rights to the image have been granted or if I had to purchase them from, for example, the press agency.
In my opinion, this renders the idea of marking an image as an Open Graph image absurd.
Maybe I'm misunderstanding something? I'm not a lawyer.
The cease-and-desist letters are already several months old, and I didn’t want to write this text in a frustrated mood. I've drawn my conclusions, but many questions remain open and perhaps this text serves as a good warning for anyone who has similar functionality on their website.
By the way, you’re welcome to use my Open Graph data, including images. They are either under an appropriate license or created by me or programmatically generated.
If you have more answers than I do, feel free to leave a comment, I’d appreciate an "aha" moment or two.
Nach meine Rechtsempfinden das durch über 200 Folgen Rechtsbelehrung gestärkt ist, halte ich die Abmahnung für nicht gerechtfertigt. Bei Abmahnung von Bilder geht es schließlich ums Urheberrecht. Hier müsste man über Schöpfungshöhe diskutieren. Vermutlich hast du letztendlich lediglich zitiert was durchaus erlaubt ist. Das erwerbsmäßige Abmahnen ist im übrigen auch bereits von Gerichten kassiert worden, genau wie die Höhe der Abmahnkosten oder angebliche Summen.
Ich hätte das Schreiben vermutlich stumpf ignoriert. Denn mit Aufwand vor Gericht schmälert den Gewinn der Abmahnindustrie und liegt gar nicht in deren Interesse
Danke für deine Einschätzung, Alex.
Ich hatte auch im Hinterkopf, dass sie wahrscheinlich genau auf Leute wie mich setzen, die das mit sich machen lassen. Meine Websuche war da nicht ganz eindeutig und ich dann auch einfach zu genervt. Hoffentlich habe ich nicht noch einmal das Vergnügen, sollte das aber doch so sein, werde ich mich vorher nochmal schlaumachen.
Gerade der Spaß mit den OG-Images wäre ja sonst auch wirklich eine enorme Kostenfalle für alle Webseitenbetreiber.
ich habe schon vor vielen jahren angefangen suchmaschinen radikal auszuschliessen. zumindest aus meinem archiv; alles was älter als 5 jahre ist, ist mit einer noindex-anweisung verbunden. für manche seiten mache ich ausnahmen, rezepte zum beispiel oder seiten bei denen mir eine dauerhafte auffindbarkeit wichtig ist. das hat zur folge, dass meine sitemap.xml gerade mal ~180 einträge umfasst bei einem archiv von >10.000 artikeln.
der grund ist ganz das was du hier beschrieben hast. ein twitter-archiv oder bilder darin lassen sich ja nur nach lizenzverstössen durchstöbern, wenn sie vorher durch und durch indexiert wurden.
google hält sich meiner erfahrung nach ganz gut an diese anweisungen, bing weniger gut.
dass das urheberrecht ein minenfeld ist, ist ja schon lange bekannt. politisch bewegt sich das ganze auch weiter in richtung tretverminen-saat. og bilder sind das eine, embeds allgemein bergen wie wahrscheinlich auch einiges an explosionspotenzial. solange man datenschutzunfreundlich nur fremdinhalte einbettet und tracking erlaubt scheint man fein raus, sobald man proxies einesetzt um aufrufe von drittanbietern zu vermeiden betritt man grauzonenland.
Darüber werde ich auch mal nachdenken, meine Sitemap ist vollumfänglich, ich kann aber im Panel einzelne Seiten ausblenden - vielleicht automatisiere ich das mal nach Datum. Den speziellen Crawler blockiere ich zudem auch htaccess Ebene. Nicht, ich habe das jetzt mit dem embeds usw. alles abgestellt, aber muss ja nicht…
Bei Embeds gibt es inzwischen auch so schöne Dinge, wie den Podcastplayer, der sich automatisch einbettet und direkt hübsch aussieht. Auch das habe ich bei mir direkt wieder deaktiviert, weil dann wieder IPs und Cookies in Richtung USA fließen… ach es geht so viel und man muss drauf verzichten, wenn man den Datenschutz im Blick behalten möchte.