Related Pages
This is how I show related pages under every post on my site.
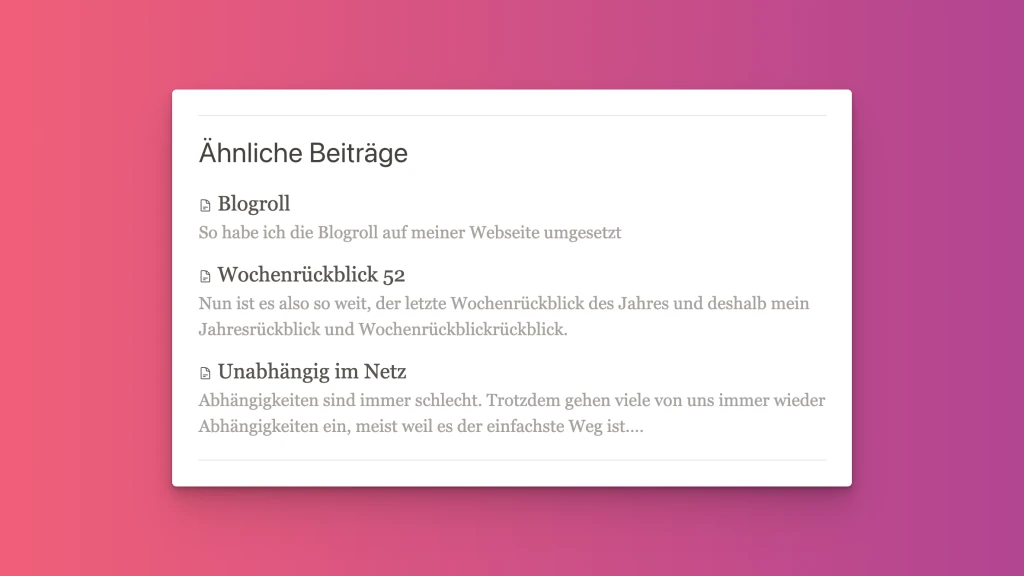
Below the posts on my website, I would like to recommend additional articles that fit the topic. In the initial versions of my website, I made these selections myself. Of course, over time, this became somewhat cumbersome, as new posts are constantly being added, and the relevance among them is constantly changing. So, I would have to repeatedly edit old articles to ensure that the connections remain accurate.
Naturally, I was not the only one who had something like this on their website. That's why corresponding Kirby plugins and this Cookbook article quickly emerged.
After some time, however, it became apparent to me that the plugins and examples offered did not deliver the results I had envisioned. Therefore, I decided to delve deeper into the topic and build my own solution.
Even beyond "Related Posts," I find the topic of "discoverability" extremely fascinating. We all probably have content somewhere on the web that we don't want to disappear into the crowd unnoticed. On a large scale, we want to be found in Search Engines, on a smaller scale, it might be recommendations to other posts on our own website.
For Kirby, there is currently a plugin that addresses the problem: Similar.
I had been using Similar for a while, but in some places, it wasn't precise enough for me, and I couldn't get it under control even by refining settings. So, I looked at how Sonja approached the issue, stole a few ideas, and adapted them to my site.
To find similar posts, I will rely on three content fields:
- Tags
- Text
- Title
Tags
I assign more or fewer tags to every post I publish. I use Kirby's Tag Field for this. My tags are global, meaning I fetch all tags from all pages and then display them as autocomplete.
In the panel, it looks like this:

The corresponding blueprint is as follows:
label: Tags
type: tags
options: query
query: site.index.pluck("tags", ",", true)
translate: falseVia query, I retrieve the contents of all tag fields to have them as autocomplete. Translation should not be possible; the tags apply to every language.
Using these tags as a source for relevant pages is straightforward. First, I fetch the tags of the current page. Then I look in all other published pages for the same tags:
$tags = $this->tags()->split(',');
$pagesWithTags = site()->index()->published()->filterBy('tags', 'in', $tags, ',')->not($this);Since I call the search for related pages in a Page Method Plugin, $this refers to the current page in all these examples. After obtaining all tags of the current page, I filter all other pages by these tags. As a result, I get a list of pages that all share at least one tag with my current page.
Since the current page would always be included in the result, I exclude it; I certainly don't want to refer to the same page.
Now I could already list all pages with the same tags, but that's not precise enough for me. What I want more is to be able to assign a weighting to the three fields mentioned above. I stole that from Sonja.
To do this, I go through all found pages again, retrieve the individual tags of each page, and only return the tags that are also stored in the current page:
If my current page has the tags kirby, cms, and plugin, and a similar page has kirby, cms, and theme, I get the two identical tags kirby and cms as a result in this way.
To remember all similar pages, I fill an array. I don't want to store the entire page at this point, but only its ID, which I can then use to access it later.
Additionally, I want to know how relevant each page really is, so I count the identical tags and calculate a weighting from them. I can change how strongly each field should be weighted later in my config.php:
foreach($pagesWithTags as $page) {
$pageTags = $page->tags()->split(',');
$similarTags = array_intersect($pageTags, $tags);
$uuid = $page->uuid()->toString();
$similarPages[] = [
'page' => $uuid,
'weight' => count($similarTags) * option('mauricerenck.similar-related.tags.weight', 1),
];
}As a result, I now have a list of pages and their respective weights.
Title
In the next step, I grab the title to recognize similarities here as well. This is not as straightforward as it was with the tags, but still relatively straightforward to implement.
To find similarities, I compare all titles word for word. To do this, I get the title of the current page and split it into its components. Then I go back to filtering all published pages, this time with my own filter.
For each of these pages, I get the title and split it into individual words. Now I have an array of words from both titles and can compare them. As with the tags, I now check if there is at least one match. If there is, I get the page as a result. And of course, I also want to exclude the current page here:
$wordsFromTitle = $this->title()->split(' ');
$pagesWithTitle = site()->index()->published()->filter(function($child) use($wordsFromTitle) {
$wordsFromChildTitle = $child->title()->split(' ');
return count(array_intersect($wordsFromTitle, $wordsFromChildTitle)) > 0;
})->not($this);Next, I fill the result array again. I go through all found pages and weight them as before. This works just like with the tags:
foreach($pagesWithTitle as $page) {
$wordsFromPageTitle = $page->title()->split(' ');
$similarWords = array_intersect($wordsFromTitle, $wordsFromPageTitle);
$uuid = $page->uuid()->toString();
$similarPages[] = [
'page' => $uuid,
'weight' => count($similarWords) * option('mauricerenck.similar-related.title.weight', 0.5),
];
}Text
Finally, we come to the most complex field type. I want to go so far as to compare every single word of the text with each other. This is a bit tricky because I also have to split the entire text into its individual words here. This can result in a pretty long word list for a long text and certainly does not contribute to the page loading faster. But more on that later.
I also use the field as a source here and split it into individual words. In this case, I only want words that are
longer than one character. This excludes some filler words like I or a in English:
$wordsFromText = $this->text()->split(' ');
$wordsFromText = array_filter($wordsFromText, function($word) {
return strlen($word) > 1;
});Now it's time to clean up; I only want "real" words:
$wordsFromText = array_map(function($word) {
return preg_replace('/[^A-Za-z0-9\-]/', '', $word);
}, $wordsFromText);Now it gets interesting. To get the most accurate result possible, I will exclude certain words. These are words that don't really have anything to do with the content. Hard to describe. Here's an example:
My page consists of this text:
I want to create a website with the CMS Kirby, for that I write myself a blueprint and a templateFor my comparison, I'm not interested in certain words at all, like I, a, with, the, to, etc. These words occur in almost every text and would dilute the result. The really interesting words here are only words like website, CMS, Kirby, blueprint, and template.
If I were to write exclusively in German, I could make my life quite easy and just fetch all capitalized words. However, this doesn't work in English.
So, what to do? I have a very long list of so-called stopwords. These are filler words, as described above. Fortunately, I'm not the only one facing such a problem, and there are some well-maintained lists out there on the web. I opted for the ISO Stopwords, which come in several languages.
The data is available to me as a JSON file. I have to load the file. First, I get the language of the current page. In my case, it's either German or English:
$pageLanguage = kirby()->language()->code() ?? 'en';
$stopWordsForLanguage = [];
$languagesJson = file_get_contents(__DIR__ . '/stopwords-iso.json');
if($languagesJson !== false) {
$stopWords = json_decode($languagesJson);
$stopWordsForLanguage = (isset($stopWords->$pageLanguage)) ? $stopWords->$pageLanguage : $stopWords->en;
}As a precaution, I check if the file could be loaded. If not, I just have an empty list. Otherwise, I check if the current language is present in the data. If not, my fallback kicks in, and I use English.
Now it's time to filter again. I remove all stopwords from the word list of the current page:
$wordsFromText = array_filter($wordsFromText, function($word) use($stopWordsForLanguage) {
return !in_array(strtolower($word), $stopWordsForLanguage);
});And now I go the usual route with a custom filter over all pages again. This time I compare the words of the text. Since I no longer have any stopwords in my source data, I don't have to filter them out for each individual page:
$pagesWithText = site()->index()->published()->filter(function($child) use($wordsFromText) {
if($child->text()->isEmpty()) return false;
$wordsFromChildText = $child->text()->split(' ');
return count(array_intersect($wordsFromText, $wordsFromChildText)) > 0;
})->not($this);I also check if the page really has a text. There could be pages that are just a listing or use blocks or layouts. I don't want them in my result and exclude them directly. I check the rest again for at least one match and include them accordingly in the list.
Now it's back to looping through all the results and filling the result arrays:
foreach($pagesWithText as $page) {
$wordsFromPageText = $child->text()->split(' ');
$similarWords = array_intersect($wordsFromText, $wordsFromPageText);
$uuid = $page->uuid()->toString();
$similarPages[] = [
'page' => $uuid,
'weight' => count($similarWords) * option('mauricerenck.similar-related.text.weight', 0.95),
];
}Now I have, at best, a very long list of similar pages. Some of these pages have the same tags, some have a similar title or text. It is possible that pages occur multiple times, which is even very likely, because if the tags are already similar, then text fragments will probably also be similar. If a page has the tag kirby, the likelihood is quite high that the word Kirby appears in the text, and therefore the page is found twice in the list.
There are two ways to deal with this:
I could exclude duplicate pages from the beginning. If I already have a list of pages with similar tags, I could exclude these when querying similar titles. With the text, I could then already exclude pages that have both similar tags and titles.
But I want to be a bit smarter about it. I assume that a page that has similar tags and a similar title and a similar text is much more relevant than a page that only shares one tag or in which a few words are the same.
Therefore, the next step is to merge the data and weight the respective page, taking into account various occurrences:
$result = [];
foreach($similarPages as $page) {
$uuid = $page['page'];
if(!isset($result[$uuid])) {
$result[$uuid] = [
'page' => $uuid,
'weight' => $page['weight'],
];
} else {
$result[$uuid]['weight'] += $page['weight'];
}
}First, I create an empty array for my result; then I go through all similar pages and get their UUID. If the page does not yet appear in my result list, I add it. I use its UUID as an array key, again I remember the UUID and the weighting.
If the page is already in the list, I don't add it again, but I add the weighting. So, if a page is in the list three times, namely with tags, title, and text, then all three weightings are added.
Finally, I have a list of all pages without duplicates, with the sum of their respective weightings. Now I want to sort them by weight:
usort($result, fn($a, $b) => $a['weight'] <=> $b['weight']);Since I can't do much with an array of UUIDs in my template, my result is converted into a page collection in the last step:
$pages = array_map(function($page) {
return page($page['page']);
}, array_reverse($result)) ?? [];As a result, I now have a collection of all matching pages, with which I can now work in the template. So, I can output the title of each page with $pageFromCollection->title();, for example, or filter my collection again.
I still have to return my collection to the template:
return new Collection($pages);I wrapped the whole construct into a plugin and provided it as a page method:
kirby::plugin('mauricerenck/related-pages', [
'pageMethods' => [
'relatedPages' => function () {
// CODE
}
];In my template, I can simply call this method, get a collection of pages back, and do something with it. I limit it to three entries and then display them in a loop:
$related = $page->relatedPages()->limit(3);
// Render related pagesA Word of Caution
I'm very satisfied with the result. The related pages displayed on the site usually fit quite well. I'm considering whether to introduce the time aspect, i.e., weighting newer pages higher than older pages.
However, it must be said: On a website with a lot of pages and/or long texts, the approach could lead to problems. A lot happens, especially in the text comparison, and this can sometimes take a long time, in the worst case leading to timeouts or memory overflows.
It would probably be smarter, therefore, not to perform the whole process with every page request, but via cron job or hook. The result could then be stored in the respective page. Nothing needs to be calculated when the page is called up.
For me, this would be the next step for my little plugin. Currently, it theoretically still runs with every page request. I don't see this as so critical for my site because I cache all pages. The cache is only cleared when I update the code of the page or the content changes. Then the above procedure is run again on page request, but then only static HTML is served. I haven't noticed any slowdowns on my site so far.
I'm considering sorting my code a bit more, maybe incorporating the above comments, and then publishing it. However, only if there is interest - Sonja's plugin works excellently after all.
Let me know if you would use the plugin!









Write a comment