Related Pages
Auf diese Weise zeige ich ähnliche Seiten unter jedem Beitrag meiner Webseite an.
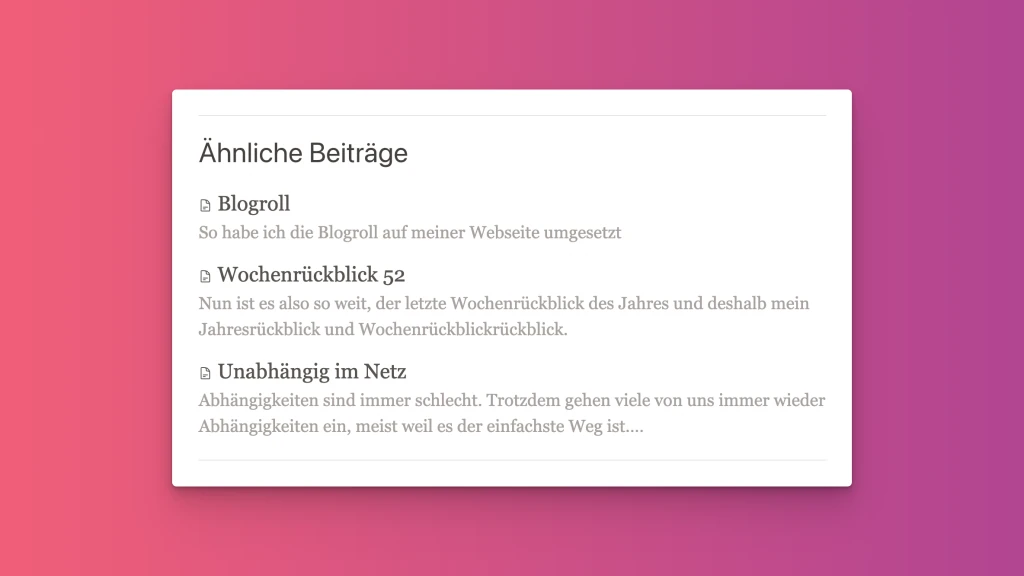
Unter den Beiträgen auf meiner Webseite, möchte ich weitere Artikel empfehlen, die zum Thema passen. In den ersten Versionen meiner Webseite habe ich diese Auswahl noch selbst vorgenommen. Das ist natürlich mit der Zeit etwas umständlich, denn es kommen schließlich ständig neue Beiträge hinzu und die Relevanz untereinander ändert sich laufend. Ich müsste also immer wieder alte Artikel bearbeiten, damit die Zuordnungen wieder stimmen.
Natürlich war und bin ich nicht der Einzige, der so etwas auf seiner Webseiten hat. Weshalb es schnell entsprechende Kirby-Plugins und diesen Cookbook-Artikel gab.
Nach einiger Zeit stelle sich für mich allerdings heraus, dass die angebotenen Plugins und Beispiele nicht die Ergebnisse lieferten, die ich mich vorgestellt habe. Deshalb habe mich dazu entschlossen, mich genauer mit dem Thema auseinanderzusetzen und eine eigene Lösung zu bauen.
Auch abseits von "Related Posts" finde ich das Thema "Auffindbarkeit" extrem spannend. Wir alle haven vermutlich irgendwo Inhalte im Netz, von denen wir wollen, dass sie nicht sang- und klanglos in der Masse untergehen. Im großen Maßstab möchte man in Suchmaschinen gefunden werden, im kleineren Maßstab sind es vielleicht Empfehlungen zu anderen Beiträgen auf der eigenen Webseite.
Für Kirby gibt es aktuell ein Plugin, was sich dem Problem annimmt: Similar.
Similar hatte ich eine ganze Weile im Einsatz, an einigem Stellen, war es mir aber nicht genau genug und das habe ich auch durchs Verfeinern von Einstellungen nicht in den Griff bekommen. Ich habe mir dann angesehen, wie Sonja die Sache angeht und mir ein paar Ideen gestohlen und auf meine Seite übertragen.
Um ähnliche Beiträge zu finden, werde ich auf drei Content-Felder zurückgreifen:
- Tags
- Text
- Titel
Tags
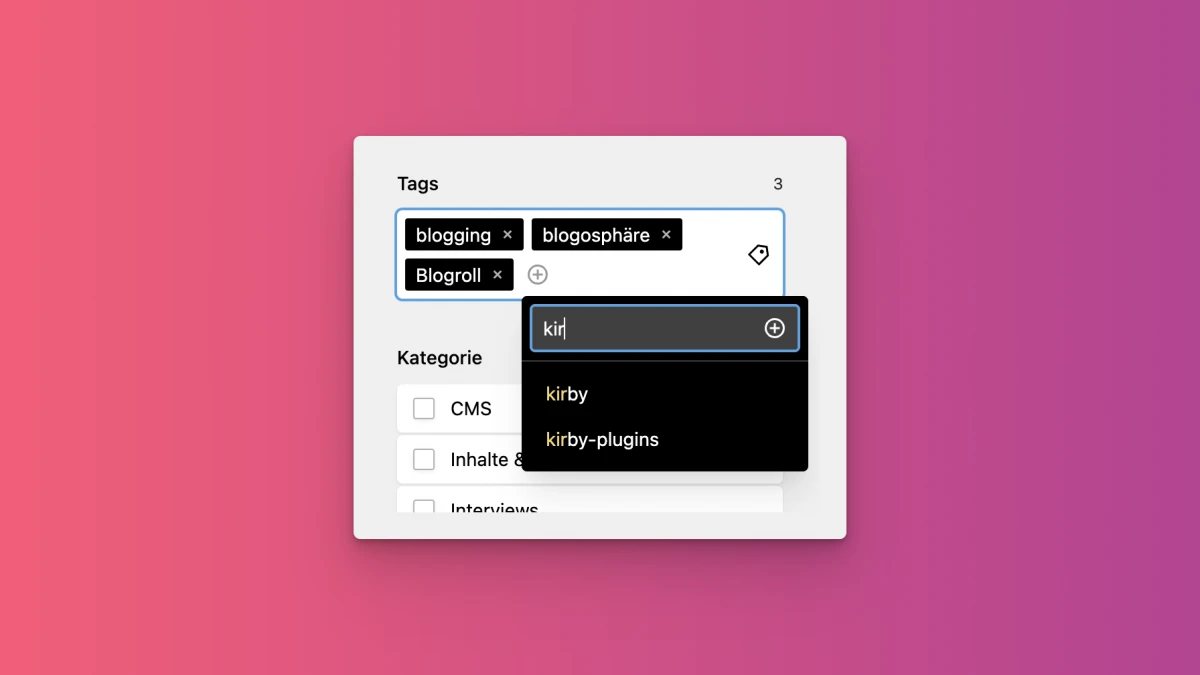
Ich verpasse jedem Beitrag, den ich veröffentliche, mehr oder weniger viele Tags. Dazu verwende ich Kirbys Tag-Field. Tags sind bei mir global, das heißt, dass ich mir von allen Seiten alle Tags hole und mir diese dann als Autocomplete anzeigen lasse.
Im Panel sieht das so aus:
Das passende Blueprint dazu wie folgt:
label: Tags
type: tags
options: query
query: site.index.pluck("tags", ",", true)
translate: false
Via query hole ich mir den Inhalt aller Tag-Felder, um diese als Autocomplete zu haben. Eine Übersetzung soll nicht möglich sein, die Tags gelten für jede Sprache.
Diese Tags als Quelle für relevante Seiten zu verwenden, ist einfach. Zunächst hole ich mir die Tags der aktuellen Seite. Dann schaue ich in allen anderen veröffentlichten Seiten nach gleichen Tags:
$tags = $this->tags()->split(',');
$pagesWithTags = site()->index()->published()->filterBy('tags', 'in', $tags, ',')->not($this);
Da ich die Suche nach Related Pages in einem Page-Method-Plugin aufrufe, verweist in all diesen Beispielen $this auf die aktuelle Seite. Nachdem ich alle Tags der aktuellen Seite habe, filtere ich alle anderen Seiten nach diesen Tags. Als Resultat bekomme ich eine Liste an Seiten, die alle mindestens einen Tag mit meiner aktuellen Seite gemeinsam haben.
Da die aktuelle Seite auf jeden Fall immer im Resultat vorkommen würde, schließe ich sie noch aus, ich will natürlich nicht auf dieselbe Seite verweisen.
Jetzt könnte ich schon alle Seiten mit denselben Tags auflisten, das ist mir aber nicht genau genug. Viel mehr möchte ich noch in der Lage sein, den drei oben genannten Feldern eine Gewichtung zu geben. Das habe ich von Sonja geklaut.
Dazu gehe ich alle gefunden Seite noch einmal durch, hole mir die einzelnen Tags jeder Seite und lasse mir nur die Tags zurückgeben, die auch in der aktuellen Seite hinterlegt sind.
Hat meine aktuelle Seite die Tags kirby, cms und plugin, die ähnliche Seite kirby, cms und theme bekomme ich auf diese Weise die beiden identischen Tags kirby und cms als Ergebnis zurück.
Um mir alle ähnlichen Seiten zu merken, fülle ich ein Array. Ich will an dieser Stelle nicht die gesamte Seite speichern, sondern lediglich ihre ID, über die ich dann später wieder auf sie zugreifen kann.
Außerdem möchte ich wissen, wie relevant jede einzelne Seite wirklich ist, dazu zähle ich die identischen Tags und errechne daraus eine Gewichtung. Wie stark jedes Feld gewichtet werden soll, kann ich später in meiner config.php ändern:
foreach($pagesWithTags as $page) {
$pageTags = $page->tags()->split(',');
$similarTags = array_intersect($pageTags, $tags);
$uuid = $page->uuid()->toString();
$similarPages[] = [
'page' => $uuid,
'weight' => count($similarTags) * option('mauricerenck.similar-related.tags.weight', 1),
];
}
Als Ergebnis habe ich nun eine Liste von Seiten und ihre jeweilige Gewichtung.
Titel
Im nächsten Schritt schnappe ich mir den Titel, um auch hier Ähnlichkeiten zu erkennen. Das ist nicht ganz so naheliegend, wie es bei den Tags war, aber auch recht unkompliziert umzusetzen.
Um Ähnlichkeiten zu finden, vergleiche ich alle Titel Wort für Wort. Dazu hole ich mir den Titel der aktuellen Seite und teile ihn in seine Bestandteile. Dann geht es wieder an das Filtern aller veröffentlichten Seiten. Dieses Mal mit einem eigenen Filter.
Für jede dieser Seiten hole ich mir den Titel und teile ihn in einzelne Worte. Ich habe nun ein Array mit Worten von beiden Titeln und kann diese vergleichen. Wie bei den Tags schaue ich jetzt, ob es mindestens eine Übereinstimmung gibt. Gibt es die, bekomme ich die Seite als Ergebnis zurück. Und natürlich möchte ich auch hier die aktuelle Seite ausschließen:
$wordsFromTitle = $this->title()->split(' ');
$pagesWithTitle = site()->index()->published()->filter(function($child) use($wordsFromTitle) {
$wordsFromChildTitle = $child->title()->split(' ');
return count(array_intersect($wordsFromTitle, $wordsFromChildTitle)) > 0;
})->not($this);
Im nächsten Schritt geht es wieder daran, das Ergebnis-Array zu füllen. Wieder gehe ich durch alle gefundenen Seiten und gewichte sie. Das funktioniert genauso wie bei den Tags:
foreach($pagesWithTitle as $page) {
$wordsFromPageTitle = $page->title()->split(' ');
$similarWords = array_intersect($wordsFromTitle, $wordsFromPageTitle);
$uuid = $page->uuid()->toString();
$similarPages[] = [
'page' => $uuid,
'weight' => count($similarWords) * option('mauricerenck.similar-related.title.weight', 0.5),
];
}
Text
Schließlich kommen wir zum aufwändigsten Feldtypen. Ich möchte so weit gehen, dass ich sogar jeden einzelnen Text Wort für Wort miteinander vergleiche. Hier wird es etwas knifflig, denn ich muss auch hier den gesamten Text in seine einzelnen Worte aufteilen. Das kann bei einem langen Text natürlich eine ziemlich lange Wortliste werden und trägt sicherlich nicht dazu bei, dass die Seite schneller lädt. Dazu aber später mehr.
Ich hole mir auch hier das Feld als Quelle und teile es in einzelne Worte. In diesem Fall möchte ich nur Worte haben, die länger als ein Zeichen sind. Das schließt im Englischen schon mal ein paar Füllwörter wie I oder a aus:
$wordsFromText = $this->text()->split(' ');
$wordsFromText = array_filter($wordsFromText, function($word) {
return strlen($word) > 1;
});
Nun geht es ans Aufräumen, ich möchte nur "echte" Wörter haben:
$wordsFromText = array_map(function($word) {
return preg_replace('/[^A-Za-z0-9\-]/', '', $word);
}, $wordsFromText);
Jetzt wird es interessant. Um ein möglichst genaues Ergebnis zu bekommen, werde ich bestimmte Worte ausschließen. Das sind Worte, die im eigentlichen Sinne nichts mit dem Inhalt zu tun haben. Schwer zu beschreiben. Hier ein Beispiel:
Meine Seite besteht aus diesem Text:
Ich möchte eine Webseite mit dem CMS Kirby erstellen, dazu schreibe ich mir ein Blueprint und ein Template
Für meinen Vergleich interessieren mich bestimmte Worte gar nicht, etwa Ich, eine, mit, dem, ein, … Diese Worte kommen in so gut wie jedem Text vor und würden das Ergebnis verwässern. Wirklich interessant sind hier nur Worte wie Webseite, CMS, Kirby, Blueprint und Template.
Würde ich ausschließlich auf Deutsch schreiben, könnte ich mir das Leben recht einfach machen und einfach alle großgeschriebenen Worte holen. Im Englischen funktioniert das allerdings nicht.
Wie also vorgehen? Ich habe eine sehr lange Liste von sogenannten Stopwords. Das sind solche Füllwörter, wie oben beschrieben. Zum Glück bin ich nicht der Einzige, der vor so einem Problem steht und es gibt ein paar gut gepflegte Listen da draußen im Netz. Ich habe mich für die ISO-Stopwords entschieden, die gleich in mehreren Sprachen daher kommen.
Die Daten liegen mir als JSON-Datei vor. Ich muss die Datei laden. Vorher hole ich mir die Sprache der aktuellen Seite. In meinem Fall ist das entweder Deutsch oder Englisch:
$pageLanguage = kirby()->language()->code() ?? 'en';
$stopWordsForLanguage = [];
$languagesJson = file_get_contents(__DIR__ . '/stopwords-iso.json');
if($languagesJson !== false) {
$stopWords = json_decode($languagesJson);
$stopWordsForLanguage = (isset($stopWords->$pageLanguage)) ? $stopWords->$pageLanguage : $stopWords->en;
}
Sicherheitshalber prüfe ich noch, ob die Datei geladen werden konnte. Wenn nicht, gibt es einfach eine leere Liste. Ansonsten schaue ich nach, ob die aktuelle Sprache in den Daten vorhanden ist. Sollte das nicht der Fall sein, greift mein Fallback und ich nutze Englisch.
Nun geht es wieder ans Filtern. Ich entferne alle Stopwords aus der Wortliste der aktuellen Seite:
$wordsFromText = array_filter($wordsFromText, function($word) use($stopWordsForLanguage) {
return !in_array(strtolower($word), $stopWordsForLanguage);
});
Und jetzt gehe ich den üblichen Weg mit einem eigenen Filter über alle Seiten. Dieses Mal vergleiche die Worte des Textes. Da ich in meinem Quelldaten jetzt schon keine Stopwords mehr habe, muss ich sie nicht auch noch bei jeder einzelnen Seite herausfiltern:
$pagesWithText = site()->index()->published()->filter(function($child) use($wordsFromText) {
if($child->text()->isEmpty()) return false;
$wordsFromChildText = $child->text()->split(' ');
return count(array_intersect($wordsFromText, $wordsFromChildText)) > 0;
})->not($this);
Ich prüfe ich noch, ob die Seite auch wirklich einen Text hat. Es könnte Seiten geben, die nur ein Listing sind oder Blöcke oder Layouts nutzen. Die will ich nicht in meinem Ergebnis haben und schließe sie direkt aus. Den Rest prüfe ich wieder auf mindestens eine Übereinstimmung und nehme sie entsprechend in die Liste auf.
Jetzt geht es wieder in die Schleife durch alle Resultate und ans Füllen des Ergebnis-Arrays:
foreach($pagesWithText as $page) {
$wordsFromPageText = $child->text()->split(' ');
$similarWords = array_intersect($wordsFromText, $wordsFromPageText);
$uuid = $page->uuid()->toString();
$similarPages[] = [
'page' => $uuid,
'weight' => count($similarWords) * option('mauricerenck.similar-related.text.weight', 0.95),
];
}
Nun habe ich im besten Fall eine sehr lange Liste an ähnlichen Seiten. Manche dieser Seiten haben dieselben Tags, manche einen ähnlichen Titel oder Text. Es kann sein, dass Seiten mehrfach vorkommen, das ist sogar sehr wahrscheinlich, denn wenn die Tags sich schon gleichen, dann werden sich vermutlich auch Textfragmente gleichen. Hat eine Seite den Tag kirby, ist die Wahrscheinlichkeit ziemlich hoch, dass auch im Fließtext das Wort Kirby vorkommt und die Seite demnach zweimal in der Liste zu finden ist.
Es gibt zwei Möglichkeiten, damit umzugehen:
Ich könnte von Anfang an, doppelte Seiten ausschließen. Habe ich schon eine Liste an Seiten, die ähnliche Tags haben, könnte ich diese beim Abfragen ähnlicher Titel bereits ausschließen. Beim Text könnte ich dann bereits Seiten ausschließen, die sowohl ähnliche Tags als auch Titel haben.
Ich möchte hier aber etwas schlauer damit umgehen. Ich gehe davon aus, dass eine Seite, die ähnliche Tags und einen ähnlichen Titel und einen ähnlichen Text hat, viel relevanter ist, als eine Seite, die sich nur einen Tag teilt oder in der sich ein paar gleiche Worte wiederfinden.
Deshalb ist der nächste Schritt das Zusammenführen der Daten und die Gewichtung der jeweiligen Seite unter Rücksichtnahme verschiedener Vorkommen:
$result = [];
foreach($similarPages as $page) {
$uuid = $page['page'];
if(!isset($result[$uuid])) {
$result[$uuid] = [
'page' => $uuid,
'weight' => $page['weight'],
];
} else {
$result[$uuid]['weight'] += $page['weight'];
}
}
Zuerst erstelle ich mir ein leeres Array für mein Ergebnis, dann gehe ich durch alle ähnlichen Seiten und hole mir ihre UUID. Taucht die Seite bisher nicht in meiner Ergebnisliste auf, füge ich sie hinzu. Als Array-Schlüssel nutze ich ihre UUID, wieder merke ich mir die UUID und die Gewichtung.
Taucht die Seite bereits in der Liste auf, füge ich sie nicht erneut hinzu, sondern addiere die Gewichtung. Steht eine Seite also dreimal in der Liste, nämlich mit Tags, Titel und Text, so werden alle drei Gewichtungen addiert.
Schließlich habe ich eine Liste aller Seiten, ohne Duplikate, mit der Summe Ihrer jeweiligen Gewichtungen. Jetzt möchte ich sie noch nach Gewicht sortieren:
usort($result, fn($a, $b) => $a['weight'] <=> $b['weight']);
Da ich in meinem Template wenig mit einem Array von UUIDs anfangen kann, wird mein Ergebnis im letzten Schritt noch in eine Page Collection umgewandelt:
$pages = array_map(function($page) {
return page($page['page']);
}, array_reverse($result)) ?? [];
Als Ergebnis habe ich nun eine Collection aller passenden Seite, mit der ich nun im Template arbeiten kann. Ich kann mir also von jeder Seite den Titel mit $pageFromCollection->title(); ausgeben lassen, oder meine Collection noch einmal filtern.
Ich muss meine Collection noch ans Template zurückgeben:
return new Collection($pages);
Das ganze Konstrukt habe ich in ein Plugin verpackt und als pageMethod zur Verfügung gestellt:
kirby::plugin('mauricerenck/related-pages', [
'pageMethods' => [
'relatedPages' => function () {
// CODE
}
];
In meinem Template kann ich indessen einfach diese Methode aufrufen, bekomme eine Collection von Seiten zurück und kann damit etwas anstellen. Ich limitiere sie noch auf drei Einträge und zeige diese dann in einer Schleife an:
$related = $page->relatedPages()->limit(3);
// Render related pages
Ein Wort der Warnung
Ich bin mit dem Ergebnis sehr zufrieden. Die Related-Pages, die auf den Seiten angezeigt werden, passen meist ziemlich gut. Ich überlege noch, ob den ich den zeitlichen Aspekt einbringe, also neuere Seiten höher gewichte, als ältere Seiten.
Was jedoch gesagt werden muss: Bei einer Webseite mit ziemlich vielen Seiten und/oder langen Texten könnte der Ansatz zu Problemen führen. Da passiert ziemlich viel, gerade beim Textvergleich und das kann unter Umständen lange dauern, im schlimmsten Fall zu Timeouts oder Speicherüberläufen führen.
Vermutlich wäre es daher schlauer, den ganzen Prozess nicht bei jedem Seitenaufruf durchzuführen, sondern via Cronjob oder Hook. Das Ergebnis könnte man dann in der jeweiligen Seite speichern. Beim Aufruf der Seite muss dann nichts mehr berechnet werden.
Für mich wäre das der nächste Schritt meines kleinen Plugins. Derzeit läuft es theoretisch noch bei jedem Seitenaufruf. Das sehe ich bei mir als nicht so kritisch an, weil ich alle Seiten cache. Der Cache wird nur geleert, wenn ich den Code der Seite aktualisiere, oder der Inhalt sich ändert. Dann wird beim Seitenaufruf das obige Prozedere durchlaufen, danach aber nur noch statisches HTML ausgeliefert. Geschwindigkeitseinbußen kann ich auf meiner Seite bisher nicht feststellen.
Ich überlege, meinen Code noch etwas zu sortieren, vielleicht obige Anmerkungen noch einzubauen und dann zu veröffentlichen. Allerdings nur, wenn Interesse besteht – das Plugin von Sonja funktioniert ja hervorragend.
Lass mich doch wissen, ob du das Plugin nutzen würdest!








